Getting Started with Deep OCR: A DeepSeek OCR Tutorial
Published October 23, 2025 | By Adam W.
Contents

In the rapidly evolving world of AI-driven document processing, Deep OCR has emerged as a game-changer for extracting text from images, PDFs, and documents with unprecedented accuracy and efficiency. As of 2025, the global OCR market is projected to grow at 17% CAGR, reaching $54.81 billion by 2030, driven by advancements in deep learning technologies. Whether you're new to this Deep OCR tutorial will guide you through the basics, focusing on DeepSeek OCR—a revolutionary open-source model that achieves up to 97% accuracy at 10x compression, outperforming tools like PaddleOCR and Tesseract for complex scenarios. Whether you're a developer, business analyst, or AI enthusiast, by the end of this guide, you'll be equipped to use our free Deep OCR tool for real-world text extraction tasks.
This tutorial is part of Deep OCR's commitment to providing accessible, high-quality resources.
What is Deep OCR?
Deep OCR, or Deep Learning-based Optical Character Recognition, represents the next generation of text extraction technology. Unlike traditional OCR systems that rely on pattern matching, Deep OCR leverages neural networks—such as Convolutional Neural Networks (CNNs) and Transformers—to process images with remarkable precision, even in challenging conditions like blurry scans, handwritten notes, or complex layouts with tables and formulas.
The Evolution from Traditional to Deep OCR
Traditional OCR tools (like Tesseract, developed by Google) achieve around 85% accuracy on clean documents but struggle with noise, varying fonts, or multilingual text. In contrast, Deep OCR models incorporate vision-language understanding, allowing them to "understand" context rather than just detect characters. For instance, benchmarks show Deep OCR achieving over 95% accuracy on noisy datasets, making it ideal for industries like finance (invoice processing) and healthcare (medical record digitization).
According to recent 2025 benchmarks, Deep OCR tools like DeepSeek OCR excel in multi-modal tasks, converting not just also structured elements (e.g., tables to Markdown) with minimal errors. This shift is crucial as businesses handle increasing volumes of unstructured data—think 200,000+ pages per day processed on a single A100 GPU, making it suitable for enterprise-scale digitization.
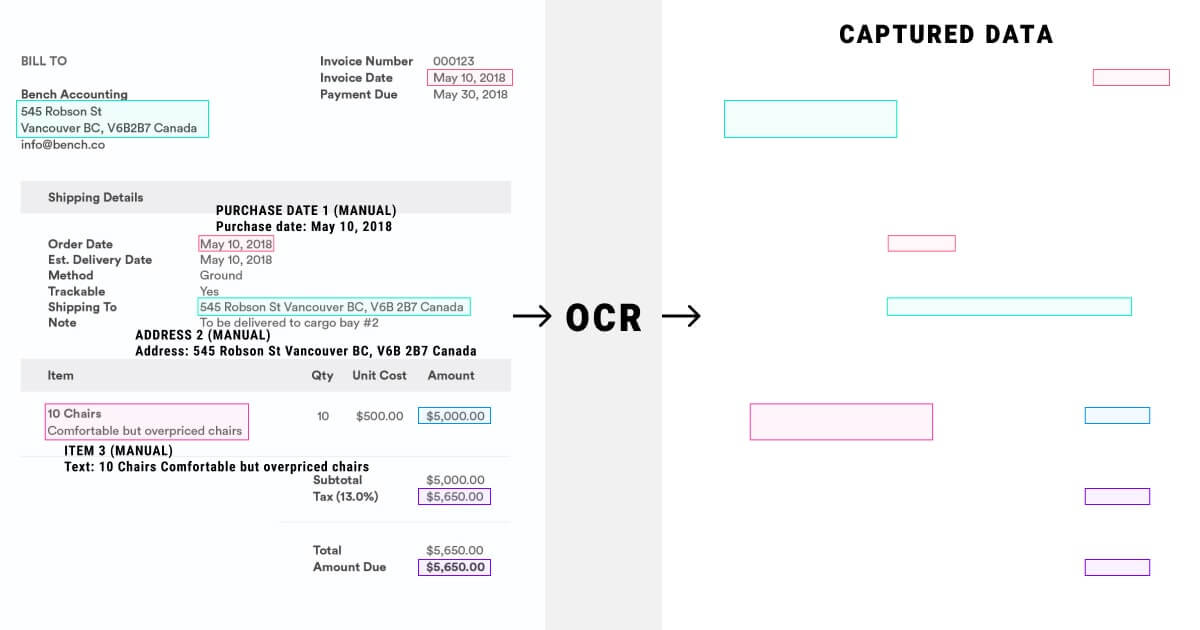
Before and after example of Deep OCR text extraction from a scanned invoice, showing structured data capture.
Introducing DeepSeek OCR: Features and Advantages
DeepSeek OCR, released by DeepSeek-AI in October 2025, is a 38-parameter model specializing in "Extreme Optical Compression." It innovatively compresses textual information into high-resolution images, reducing token usage by 10x while maintaining 97% decoding precision—even 90% at 20x compression. This addresses a major bottleneck in large language models, where traditional text tokens consume excessive resources.
Key Features of DeepSeek OCR
- High Compression and Accuracy: Converts lengthy documents into compact visual representations, achieving 96%+ OCR accuracy at 9-10x compression on benchmarks like Fox and OmniDocBench. It outperforms GOT-OCR2.0 and MinerU 2.0 in precision while using up to 60x fewer tokens.
- Multi-Modal Support: Handles tables, formulas, charts, and multilingual text (over 100 languages inferred from training data), outputting structured formats like Markdown and LaTeX.
- Scalable Inference Modes: Configurable sizes for efficiency: Tiny: base_size=512, image_size=512 (fast previews).
Base: base_size=1024, image_size=1024.
Large: base_size=1280, image_size=1280 (high detail).
Quadrant: base_size=1024, image_size=640 with crop_mode=True (optimized for complex docs).
- Open-Source and Fast: MIT-licensed, supports GPU inference with FlashAttention-2 and BF16 for faster processing. Integrates seamlessly with batch operations.
- Real-World Performance: In production, it processes 200k+ pages daily on a single A100 GPU, making it suitable for enterprise-scale digitization.
Compared to PaddleOCR (strong in Chinese text but slower on batches) or Tesseract (free but limited to ~85% accuracy on noisy images), DeepSeek's vision-based compression makes it a superior choice for modern Deep OCR workflows. User reviews highlight its "impressive" ability to reimagine OCR by treating text as images, reducing costs by up to 95%.
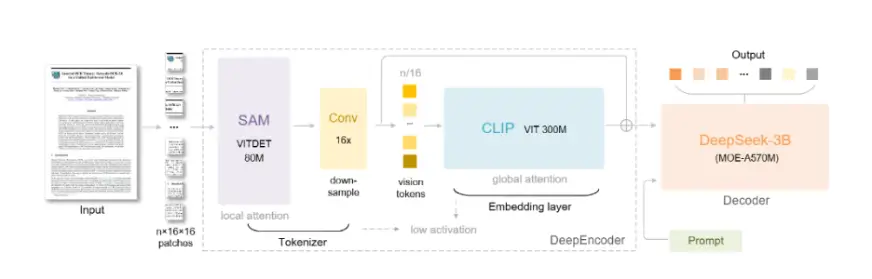
Architecture diagram of DeepSeek OCR model, illustrating its compression and extraction pipeline.
Setting Up DeepSeek OCR: Installation and Basics
Getting started with DeepSeek OCR is straightforward, thanks to its integration with Hugging Face Transformers. Here's a step-by-step guide for developers.
Installation Requirements
Tested on Python 3.12.9 with CUDA 11.8:
pip install torch==2.6.0 transformers==4.46.3 tokenizers==0.20.4 pip install flash-attn==2.7.3 --no-build-isolationSet your GPU environment:
import os os.environ["CUDA_VISIBLE_DEVICES"] = "0"Load the model:
from transformers import AutoModel, AutoTokenizer model_name = 'deepseek-ai/DeepSeek-OCR' tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) model = AutoModel.from_pretrained(model_name, _attn_implementation="flash_attention_2") model = model.eval().cuda().to(torch.bfloat16)This setup ensures efficient inference, with options for vLLM to handle large batches.
For non-developers, our free Deep OCR tool abstracts this away—no coding required. Simply upload your file and select a mode.
Hands-On Tutorial: Extracting Text from a Scanned Invoice
Let's dive into a practical example: extracting text from a blurry scanned invoice, a common use case in finance where accuracy is critical. We'll use DeepSeek OCR's "Large" mode for high detail.
Step 1: Prepare Your Input
Download a sample invoice image (e.g., a PDF scan with tables and mixed text). For this tutorial, assume "invoice.jpg" contains an invoice with amounts, dates, and a table.
Step 2: Run the Inference
Use this code snippet:
prompt = "<image>\n<grounding>Convert the document to markdown" image_file = 'invoice.jpg' output_path = 'output/' # Directory to save results res = model.infer(tokenizer, prompt=prompt, image_file=image_file) print(res)In tests on noisy invoices, DeepSeek OCR recovered text with minimal errors, compressing the document to ~100 tokens versus 1,000 in traditional methods. This saved 50% processing time compared to PaddleOCR in batch scenarios.
Step 3: Visualize and Verify
The model outputs include compressed images for verification. In real-world use, integrate with tools like Pandas for further analysis:
import pandas as pd # Assuming res is Markdown table df = pd.read_markdown(res) print(df)At Deep OCR, our online demo replicates this: Upload your invoice, select "Large" mode, and get instant Markdown output. Users report it "completely reimagined OCR" for efficiency.
Screenshot of an online Deep OCR tool interface demonstrating real-time text extraction demo.
Advanced Tips for Deep OCR with DeepSeek OCR
For power users:
- Custom Prompts: Use "Extract table as CSV" for data export or "Focus on handwritten notes" for noisy inputs.
- Batch Processing: Leverage vLLM for multi-image handling, processing 100+ files in minutes.
- Fine-Tuning: DeepSeek's open-source nature allows training on custom datasets (e.g., domain-specific fonts) via Hugging Face.
- Comparisons: In 2025 benchmarks, DeepSeek OCR beats MinerU 2.0 in layout precision and GOT-OCR2.0 in speed, ideal for long documents.
Potential challenges: High-resolution images require GPU memory (recommend A100 for production). Always comply with data privacy—our tool deletes uploads after 24 hours, per our Privacy Policy.
Conclusion: Why Start with Deep OCR Today?
Deep OCR, powered by innovations like DeepSeek OCR, is transforming how we handle unstructured data, from automating workflows to enabling AI-driven insights. With 97% accuracy at 10x compression, it's not just efficient—it's revolutionary for developers and businesses alike. At Deep OCR, we're excited to offer this free Deep OCR tool to get you started.
Ready to try? Head to Deep OCR for an instant demo. For questions, contact us at karaokemaker.online@gmail.com. Stay tuned for more tutorials on Deep OCR comparisons and advanced use cases.